Machine Learning
This documentation describes Heartex platform version 1.0.0, which is no longer supported. For information about setting up machine learning in Label Studio Enterprise Edition, the equivalent of Heartex platform version 2.0.x, see Set up machine learning.
One of the advantages of using Heartex is the possibility of annotating datasets automatically using machine learning (ML). Why is this important? Automatic annotations are just insights on the top of the dataset. You can leverage intelligence in different scenarios:
Heartex annotates tasks automatically using its pre-trained ML models or custom ones connected through SDK. This means you can automate the processes of finding relevant insights automatically. E.g., analyze customer feedback in real-time, or identify the objects in the images.
Automatic annotations can boost annotator performance. Tasks are pre-labeled by ML models, and annotators only need to correct wrong predictions. Heartex learns from the feedback and provides more accurate results with each iteration.
Introduction
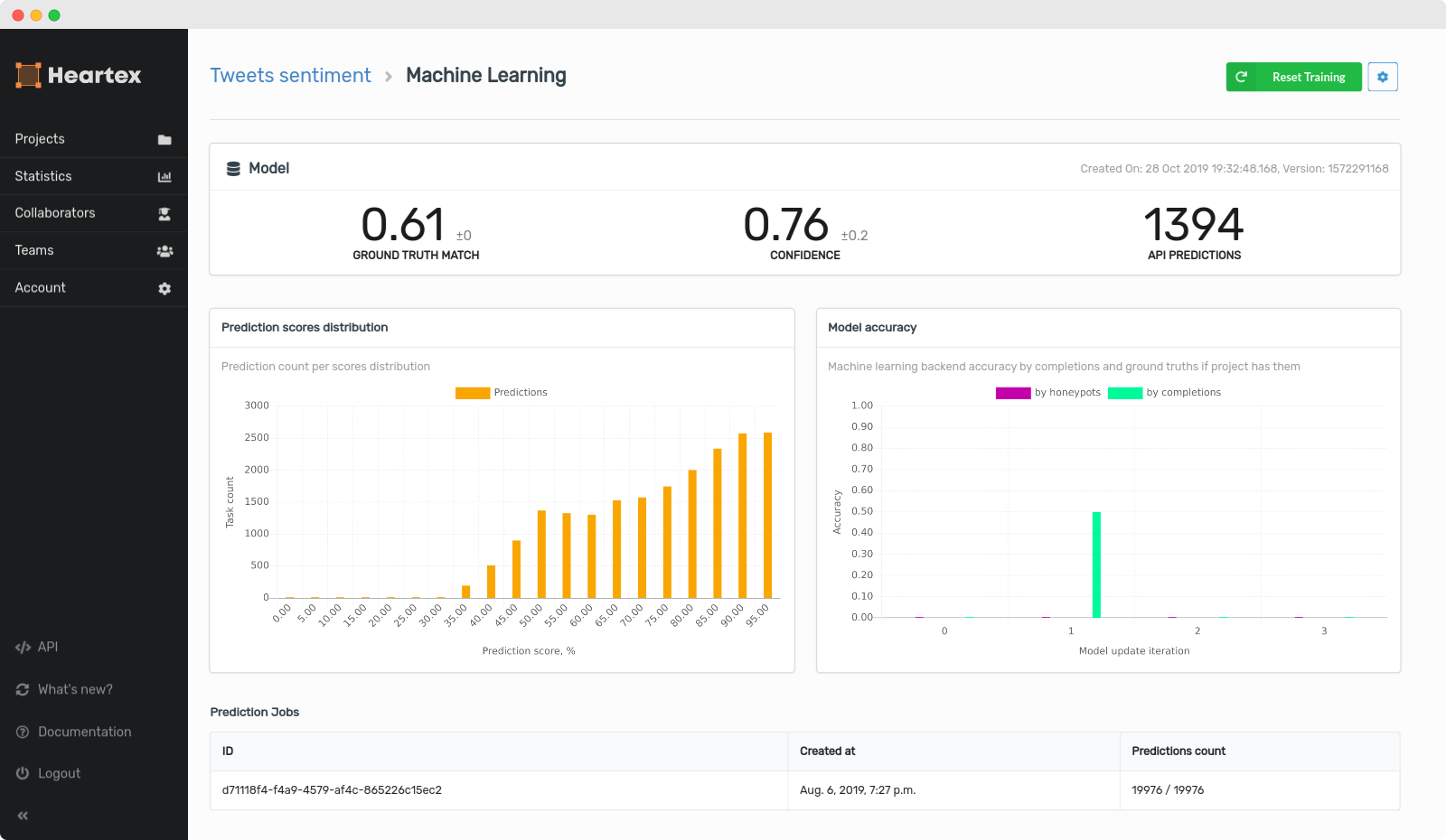
You can set up machine learning under Machine Learning tab on Settings page:
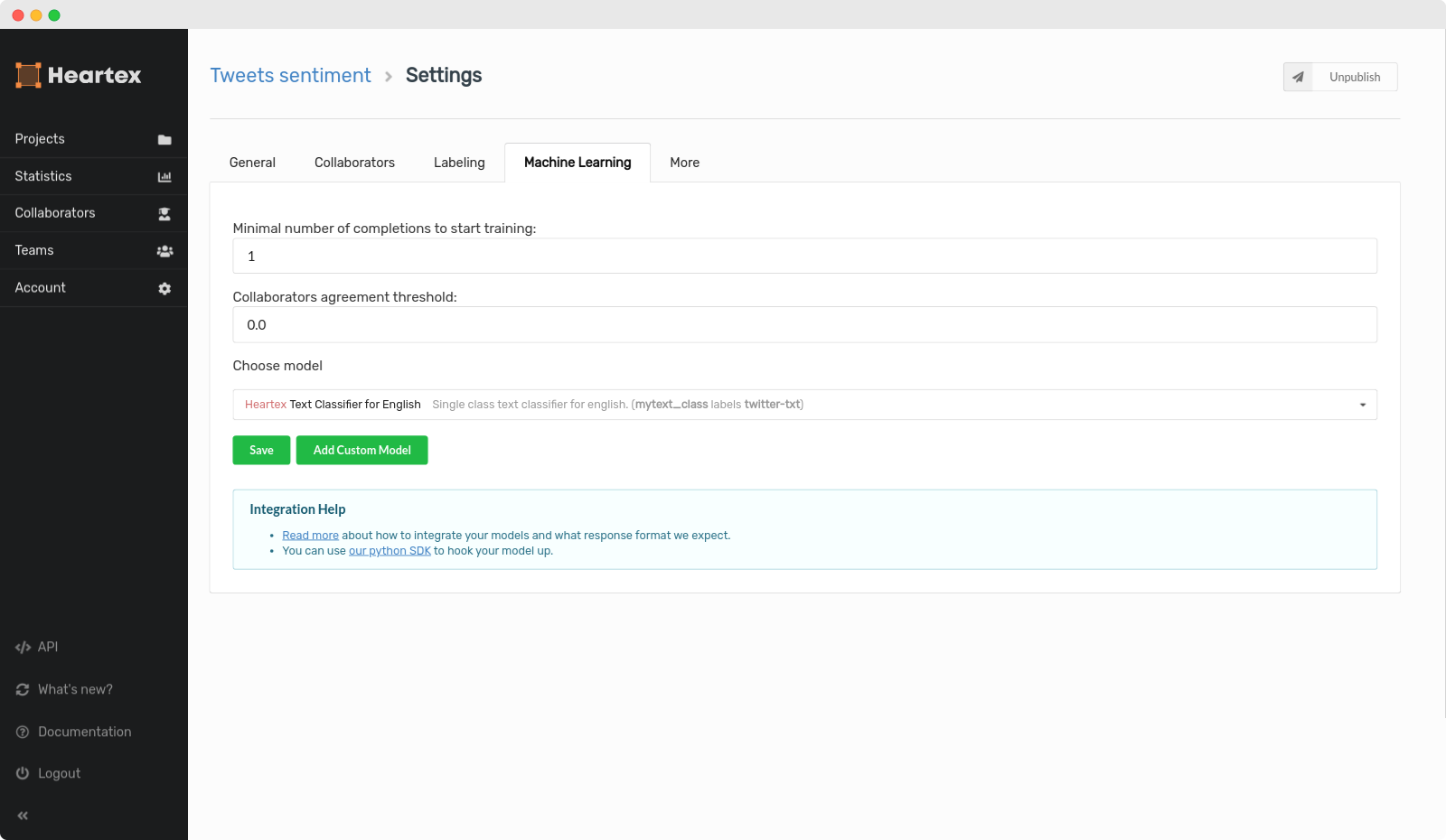
The following options are available:
Minimal number of completions how much items from your dataset needs to be manually labeled before model starts its training process
Collaborators agreement threshold whats the agreement threshold for the items to get accepted into the training.
Choose model option lists all available models for the current project. Note that models are filtered by the data types and labeling schemes present in the editor config.
Besides internal ML backends, you can also connect your backend using Add custom model button. For running ML backend, it is recommended to use our Heartex SDK.
Active Learning
The process of creating annotated training data for supervised machine learning models is often expensive and time-consuming. Active Learning is a branch of machine learning that seeks to minimize the total amount of data required for labeling by strategically sampling observations that provide new insight into the problem. In particular, Heartex Active Learning algorithms seek to select diverse and informative data for annotation (rather than random observations) from a pool of unlabeled data. Active learning algorithms are a cornerstone of the Heartex platform, allowing users to utilize these methodologies with minimal costs to projects or configuration requirements.
Due to the lack of a universal “one size fits all” active learning algorithm, Heartex provides several options. Additionally, the first batch is always chosen randomly, both because there must be sufficient training data for Active Learning to work and to mitigate initial bias.
Active Learning is automatically enabled when you configure your project to use Machine Learning. You can set how items are sampled for labeling inside the Labeling tab project Settings.
Predictions
If Machine Learning is enabled, you can use Heartex API to make predictions for the new data samples.
Read more in API documentation.