[v1.2.0] 2 February 2020
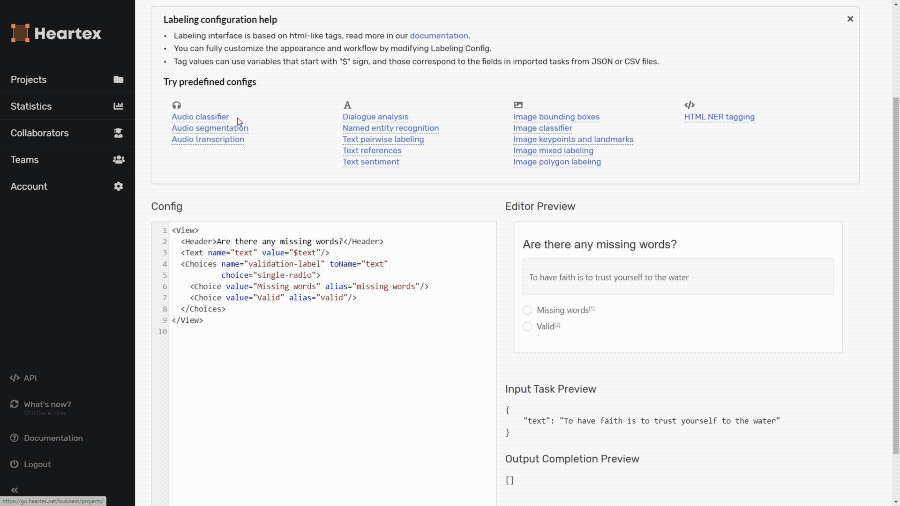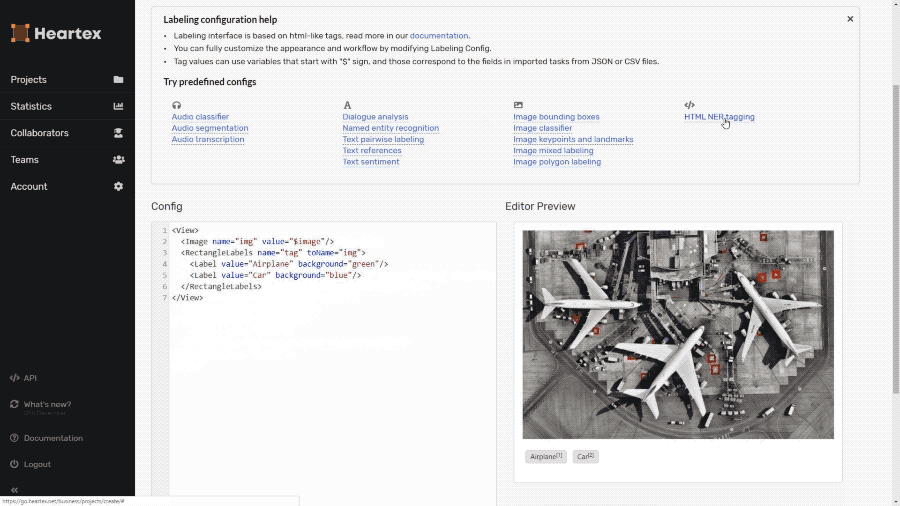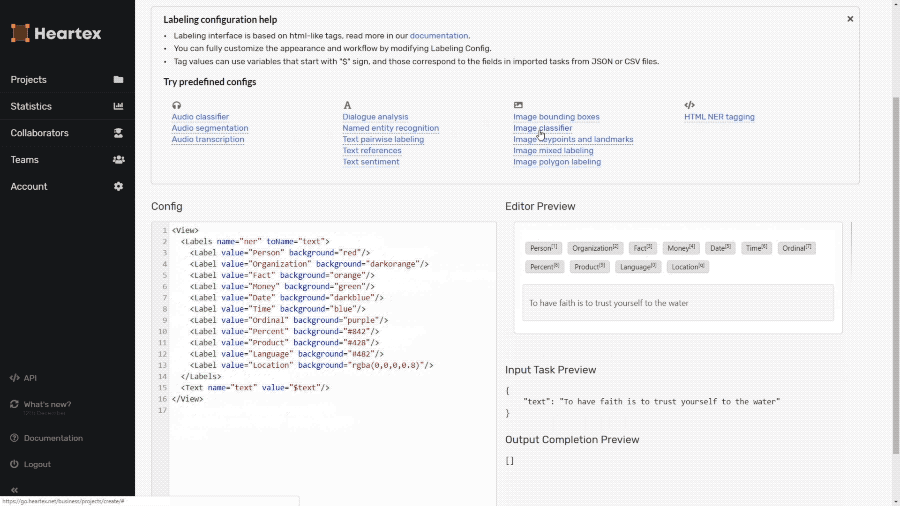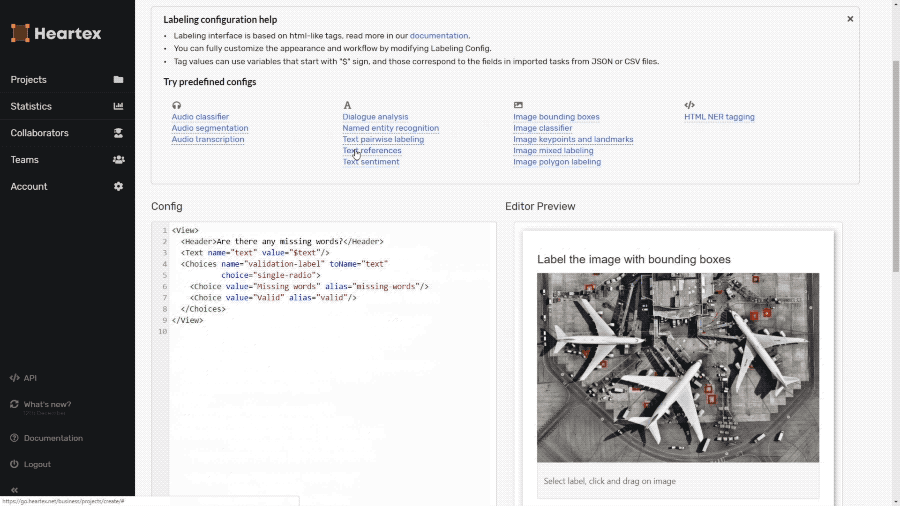
For the last month, we’ve been exploring the possibilities of integrating the labeling into our customer’s products, and the results we’ve seen were terrific. White labeling the annotation interface can enable you to collect information from your users all within your product. Next, you can analyze that data inside the Heartex platform and train the machine learning model with it. Here is what it may look like for the text parsing:
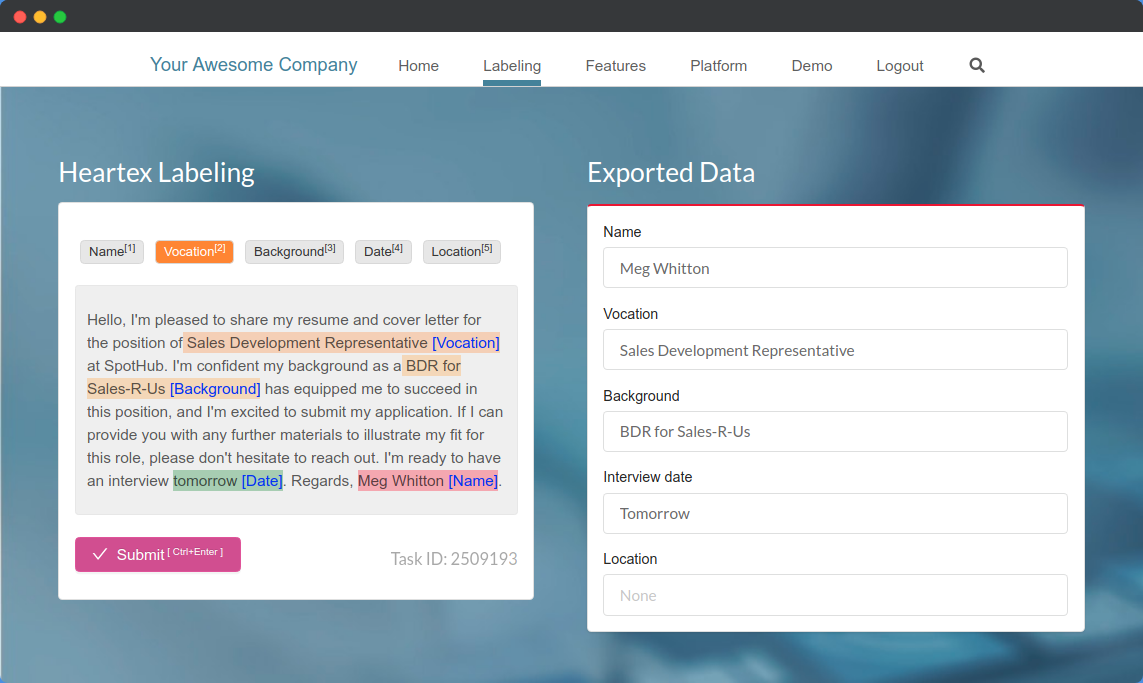
Introducing Embeddable Labeling for your products
One of the best labels you can get may come from the users of your product. But how can you tap into your user-base? That’s the question we’ve tried to answer while developing Heartex JavaScript SDK. Instead of inviting users to our platform, you can embed the labeling interface directly into your product. Moreover, with the introduction of the <Style> tag, you can style the interface to follow your design guides. You don’t lose the relationship with your users, sending them over to other third party services. Instead, you get a seamless integration and can capture the labels and further manage it through Heartex Data Manager.
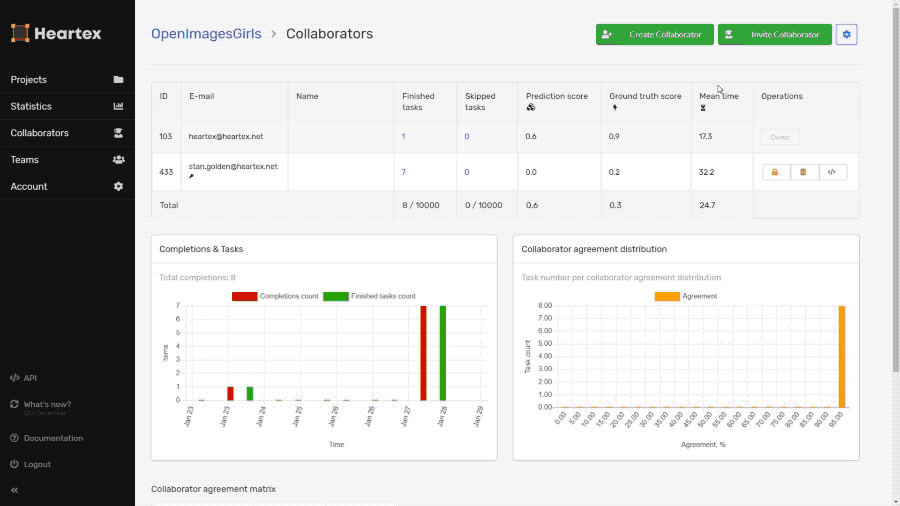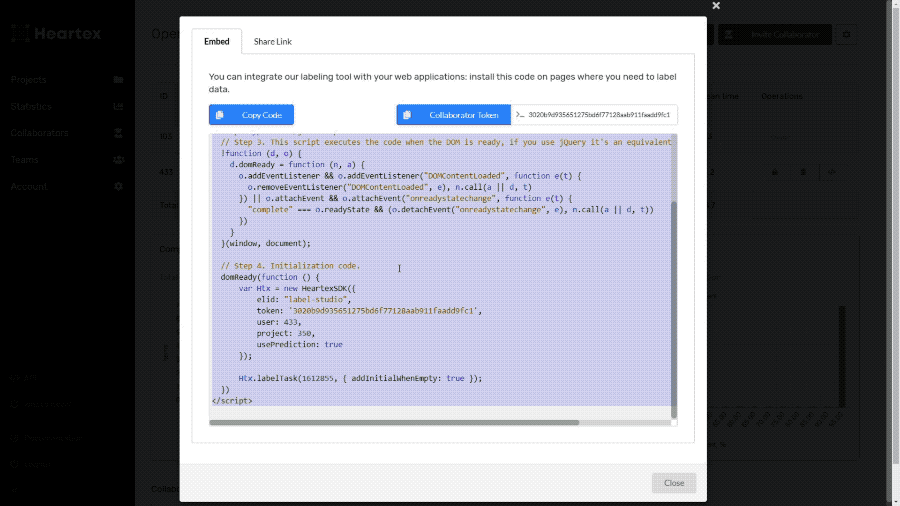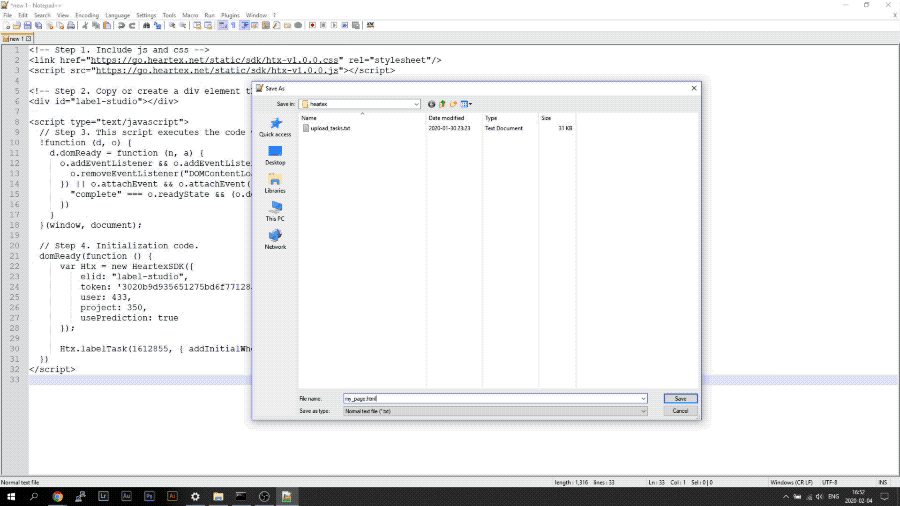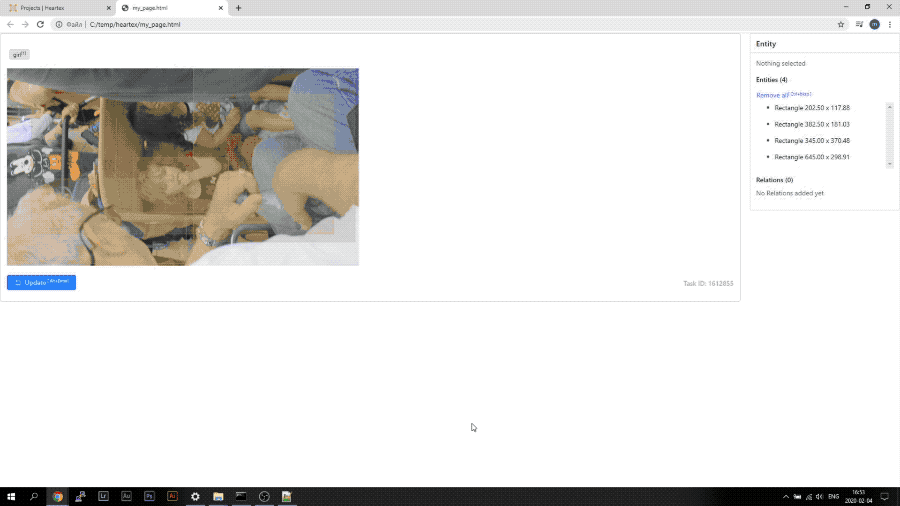
Shareable Quick Links for annotators
Using the links, you can share labeling tasks without the need for registration, which makes it possible to email it or send it via instant messenger and start getting results immediately.
Reworked polygon segmentation
Image segmentation with polygons was significantly simplified. Just try it yourself.
Platform Updates
Data Manager Filters
Now you can easily filter tasks based on one or more intersected filters:
- Search inside task data
- Search within labels and values of completion results
- Search within labels and values of prediction results
- Filter tasks completed by specified collaborator
New templates in create project
New templates are grouped together by data type (text, audio, html, images) to speed up project configuration.
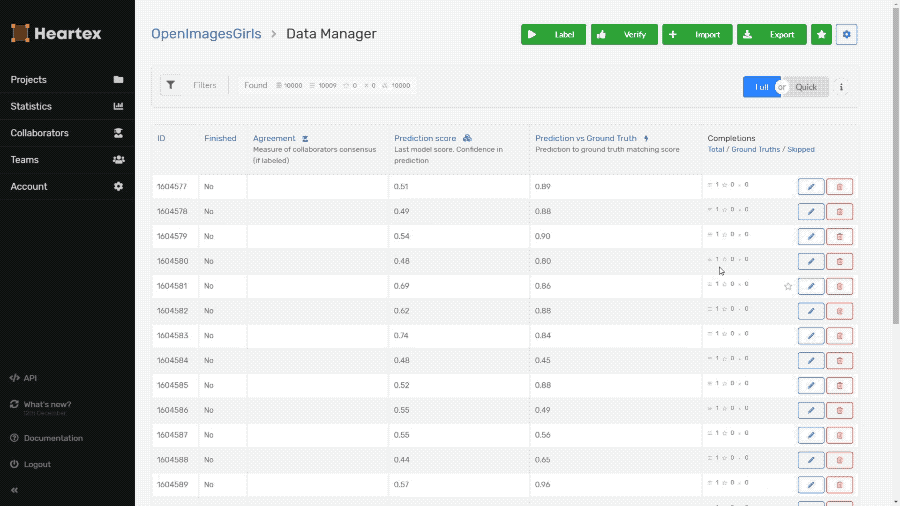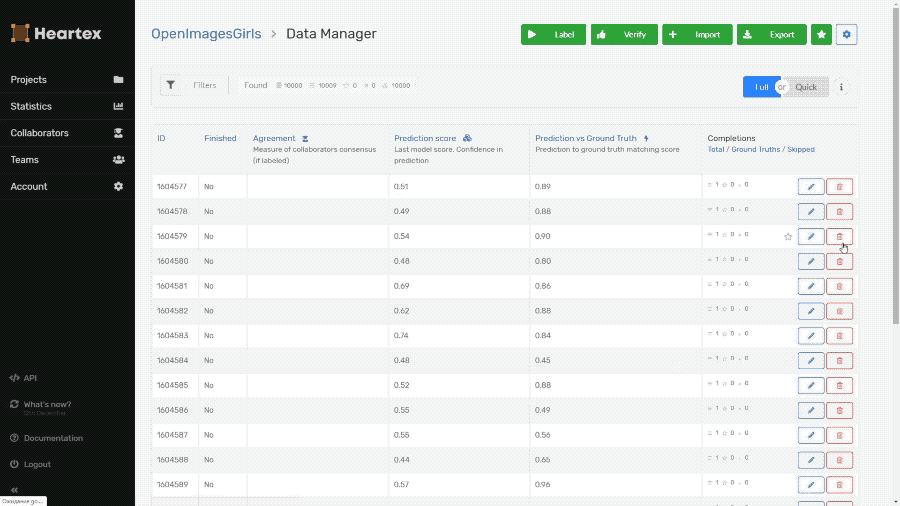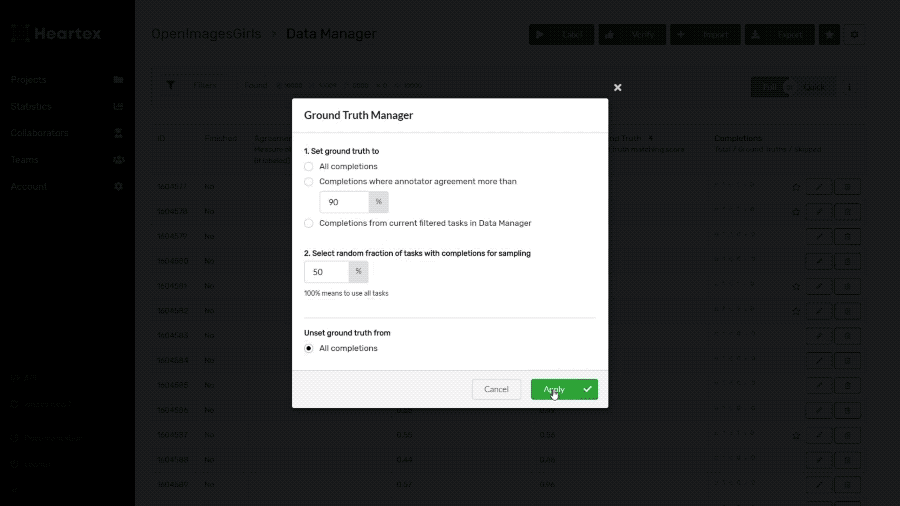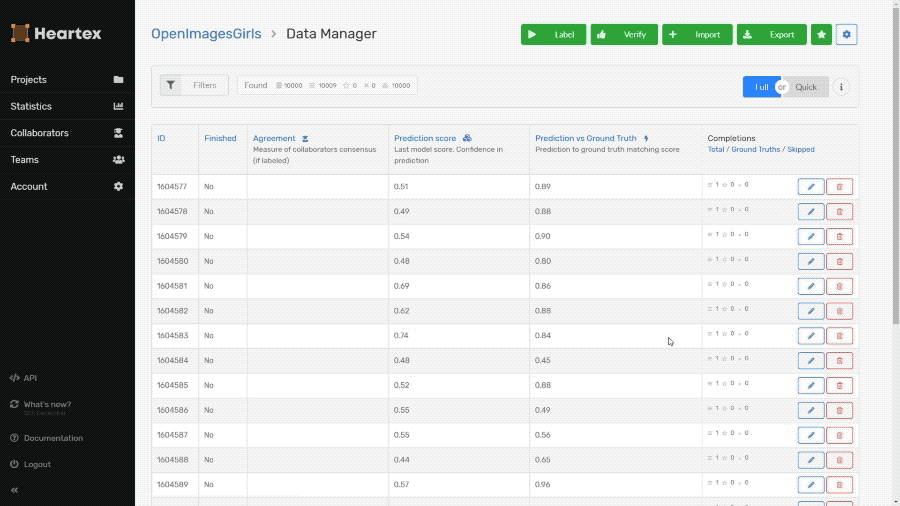
Ground Truth manager
Ground Truth (GT) is a special type of completion. Use GT to exclude completions from training and then
make cross-validation on these items. The Ground Truth manager helps you to select multiple completions by random sampling and mark them all as GTs. It also works well together with different filters: by collaborator, by agreement rate, by search among task data, completion, or even prediction results.
Import Predictions using the API
You can upload tasks with predictions, that is useful for pre-labeling, statistics building, version monitoring of ML models. Learn more about it in API documentation.
Automatic estimates of mislabeling score
[Experimental feature] After labeling your first task, the data manager automatically tries to infer the mislabeling score. You can sort tasks based on that and explore possible annotation errors.
Refreshed UI
Styling has changed to become easier on your eyes: all fonts are lighter, and colors are brighter. Feel fresh while using the platform!
Misc
- Added last export files to export dialog.
- Added prediction reset button on ML page.
- Now machine learning model updates whenever you are doing any operations with completions:
adding new completion, deleting or editing existing completions. - Updated emails for user registration, password recovery and others
- API Response Refactoring: “detail” is always in API response on errors.
- Support metrics and statistical plots for HTML tagging and pairwise comparison labeling projects.
Fixes
- Fixed hanging while exporting tasks with predictions.
- Fix docs about project membership.
- Fix with dashboard permissions.